2023. 7. 14. 16:52ㆍ카테고리 없음
학습 방법론:
Supervised, Unsupervise, Reinforcement
훈련할 데이터셋이 정답을 포함하는 경우 -> Supervised Learning
Based on pre-classified examples.
Classfication. 데이터셋에서 데이터 각각을 instance마다 Label이 되어있는데 Predictor가 학습을 통해
새로운 Instance가 생성된다. Classifier가 traning data를 가지고 unseen data를 가지고 분류를 할 것이다.
clustering : traning data가 주어지지만 레이블이 없기 때문에 속성값을 가지고 비슷한 값들끼리 모은다.
regression: 값을 예측하는 정도이고 앞에 두 용어는 분류하는 느낌이다. Logistic regression은 claasification한 느낌이다. 일반적으로 Linear regression을 많이 사용한다. 회귀라는 말은 예측과는 거리가 멀지만 나름대로 이유가 있다고 한다.
Supervised Learning Algorithms:
K-Nearest neighbors
Linear Regression
Logistic Regression
Support Vector Machines
Decision Trees and Random Forests
Neural networks
Unsupervised Learning Algorithms
훈련 데이터가 정답을 가지고 있지 않은 경우이다. Predictor는 Teacher가 없이 훈련을 한다. 그래서 공통 특성을 갖고 있는 것끼리 그룹핑한다. 데이터를 가지고 학습을 시키는 경우를 보면 대부분 Label이 되어있지 않다.
Examples:
K-Means
DBSCAN
PCA
t-SNE
시각화 알고리즘은 데이터를 시각화하면 clustering됩니다.
Clustering: 비슷한 인스턴스끼리 묶는다. 이 데이터들이 가지고 있는 속성끼리 묶는다. 훈련데이터는 각 인물마다 훈련영상이 필요해서 traning data는 많이 필요하다. 동영상을 input으로 넣으면 각 인물마다 가지는 특성을 추출해서 1500개의 폴더를 생성한다. 각 폴더마다 동일한 인물끼리 들어간다. 안 그러는 경우는 노이즈라고 한다.
차원축소 : 상관성이 높은 몇 가지를 뭉칠 수 있다.
Anomaly dectection : 사기를 막는거, 불량 생산품 찾기 등
Google Photos
Reinforcement Learning : 환경이 주어지고 관찰한다. 기본적인 policy을 선택하다. 액션을 취하고 상또는 벌을 받는다. policy을 업데이트한다. 최적의 정책이 만들어질 때까지 반복한다. 자가학습을 통해서 벌을 받기도 하고 보상을 받기도 한다.
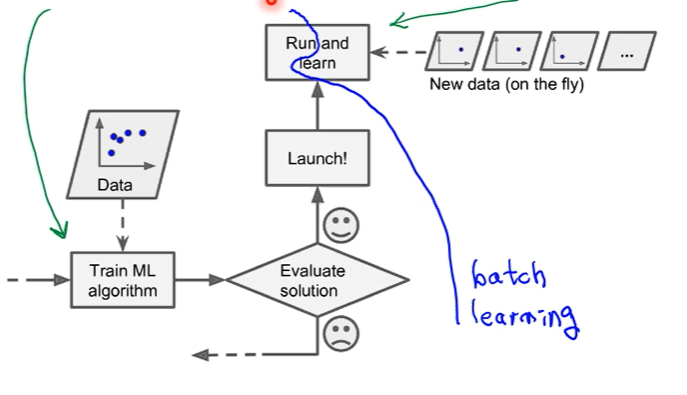
Batch learning and online learning: 한번에 학습을 할지, 현장에 따라서 점진적으로 학습을 할 지 고민하는 것이다.
우선 시스템이 학습을 다한다. 한 번에 학습을 하는 경우 시간이 오래 걸린다. Online Learning은 점진적으로 훈련해서 소그룹으로 들어올 수도 있다. 비용이 적게 들고 빠르다. 즉시 들어오는 데이터를 학습을 한다.
Simple Predictor:
Predictor가 하는 일은 예측, 분류을 하는 일이다. 학습 방법으로는 기계학습 또는 deep learning이 있다.
모델링이라는 것은 어떤 것을 인풋으로 넣고 아웃풋을 얻을것인가?
직선 함수를 모델링하고 싶다. 직선을 함수로 표현한다. 기울기는 가중치이다. 기울기와 bias로 예측한다. input은 GDP_per_capita이고 아웃풋은 life_satisfaction이다. 선형 모델로 두개의 파라미터를 가지고 있다. 위 처럼, 기울기랑 bias이다. 정밀하게 조정하는 것은 tweaking이라고 한다. 이 모델을 선형 함수로 표현할 수 있다. 가장 근접한 직선 모델을 하려면여러 학습을 거쳐 tweaking을 해야한다.
얼마나 정확한지 측정하는 방법이 필요하다. cost function을 정의해야 한다. cost function 값이 높으면 정확성이 떨어진다.
각 점들과 직선과의 거리 distance가 에러이다. 이 모델을 훈련시키는 것은 차차 배울 예정이다. 모델을 traing하는 것은 알고리즘을 수행해서 최적의 파라미터를 찾아낸다. 학습 알고리즘으로 얻은 파라미터로 최적의 linear한 함수를 얻어낸다.
머신러닝 시스템 개발에 어려운 점
알고리즘이 잘못되거나 데이터가 좋지 않을 때 학습이 올바르지 않다. 매우 단순한 문제에서도조차 수많은 traingset data가 필요하다. 복잡한 문제의 경우는 수백만개의 데이터가 필요하다. 여러 개의 알고리즘이 있을 때, 이런 것들은 단순한 것도 있고 복잡한 것도 있지만, 데이터가 많이 확보된다면 비슷한 성능을 낼 수 있다.
training data가 일반화되기 위해서는 새로운 케이스에서도 대표성을 가져야한다. 저소득 국가에 GDP와 고소득 국가에 GDP를 넣었을 때 새로운 분포를 보여준다. 기존의 데이터들로 훈련한 모델과 비교했을 때 예측과는 다른 아웃풋이 나타난다. 따라서 훈련을 할때 모든 경우를 포함하도록 반영해야한다.
데이터 품질이 나쁜 경우 (에러도 많고 아웃라이어도 있고 노이즈도 있을 때)
적합도가 떨어진 데이터일 때
Feature Engineering은 특징 선택, 특징 가공 및 추출, 새로운 데이터 수집 하는 일을 한다.
예를 들어 Feature을 선택한다는 것은 x1과 x2 입력값을 고른다는 것이다. 일차적으로 얻어낸 Feature을 이용해서 새로운 Feature을 만든다. 새로운 모델을 만든다.
과적합이라는 지나치게 특정 케이스에 맞춘 값이다. 이런 경우, 우리의 모델이 뛰어난 성능이 일어나지만, 일반적으로 사용하지 않는다. 고차다항식으로 표현된 모델은 지나치게 overfitting되어서 단순한 모델보다는 성능은 좋지만 현장에서 쓰기에 신뢰할 만한가의 문제점이 있다. overfitting을 완화하기 위해 제약을 걸어준다. Regularizion
일반화시킨 모델은 소수의 모델에서는 정확하지 않아보일 수 있지만, 새로운 데이터가 들어온 경우 Prediction이 정확하게 나올 수 있다. 반대로 제대로 fitting하지 못한 경우 학습이 잘 되어 있지 않다고 판단한다. 직선 모델은 underfit한 경향이 크다. 왜냐면 현실 문제는 보다 복잡하기 때문이다. 이를 고치기 위해서는 강력한 모델을 선택하고 더 나은 Features를 선택하고 규제를 줄인다.
Testing과 Validating
우리의 데이터는 크게 traing data와 testing이 있다. 다시 training 은 training과 validation으로 나뉜다.
퀴즈1. C
퀴즈2. A
퀴즈3. 헷갈림 Supervised가 지도 학습이였나?
퀴즈4. B
퀴즈5. B
퀴즈6. B